
- Around 75% of sites blocking OpenAI or Google AI bots still appeared in AI citations.
- Roughly 95% of the cited pages blocked GPTBot or Google-Extended, the bots used for model training.
- About 70% of ChatGPT citations came from sites blocking ChatGPT-User or OAI-SearchBot, which power live retrieval.
Another myth busted.
One way many publishers have been trying to prevent AI from using their data is by blocking AI crawlers with a robots.txt file.
I mapped the top news publishers blocking AI crawlers in our post for both the UK and the US.
Now, I wanted to put this data to the test to see if blocking crawlers prevents citations.
Using data from Citation Labs’ AI citation-tracking tool, XOFU, we examined 4 million citations from 3,600 prompts in ChatGPT, Gemini, AI Overviews, and AI Mode, across 10 industries.
Note: This is part three of a multi-part analysis of this data. Part one is about the role of news in AI citations, and part two is about the impact of AI partnerships on news citations.
Here’s what the data shows about AI crawlers blocking AI citations.
The Bots We Are Looking At
Each AI tool has a specific bot that crawls through the web and gathers information.
For our study, we focused on bots powering ChatGPT, Google AI Mode, AI Overviews, and Gemini.
Some bots crawl information to train AI models. Others gather information for live retrieval/search, which, as far as we understand, is when citations are generated.
| Category | ChatGPT | |
|---|---|---|
| Training | GPTBot | Google-Extended (Gemini) |
| Retrieval / Live Search | ChatGPT-User, OAI-SearchBot |
Googlebot |
Sites can add crawl instructions for these bots in a robots.txt file.
For instance, here’s what Yahoo’s robots.txt file looks like:
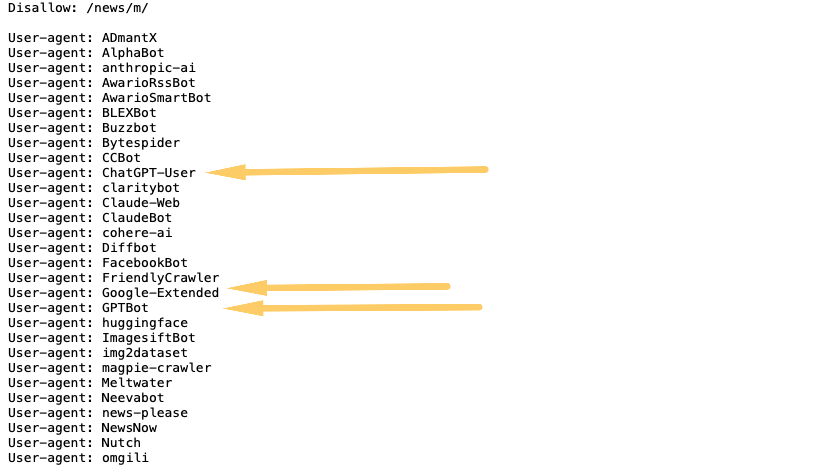
In this robots.txt file, they are attempting to block the ChatGPT-User, Google-Extended, and GPTBot from crawling the site.
This, as we’ll see, isn’t foolproof, and bots can still circumvent the robots.txt directive.
So, let’s get into it.
Sites That Block ChatGPT
Based on our study of the top 50 news sites that block ChatGPT’s live retrieval and search bots:
- 70.6% of the sites that block ChatGPT-User, which is involved in retrieval, still appear in the dataset’s AI citations.
- 82.4% of sites that block OAI-SearchBot, which is involved in search features, still appear in the dataset’s AI citations.
- 88.2% of the sites that block GPTBot, which is involved in training, still appear in the dataset’s AI citations.
Typically, when ChatGPT shows links or sources, they come from a retrieval pipeline rather than the training dataset, as far as we know.

For example, when we conducted our first study, we found that cnbc.com blocked virtually everything, including ChatGPT-User, GPTBot, and OAI-SearchBot, yet it still appeared 1,298 times in our dataset.
Sites That Block Google
92.30% of the sites that block Google-Extended, which is involved in training, still appear in the dataset’s AI citations.
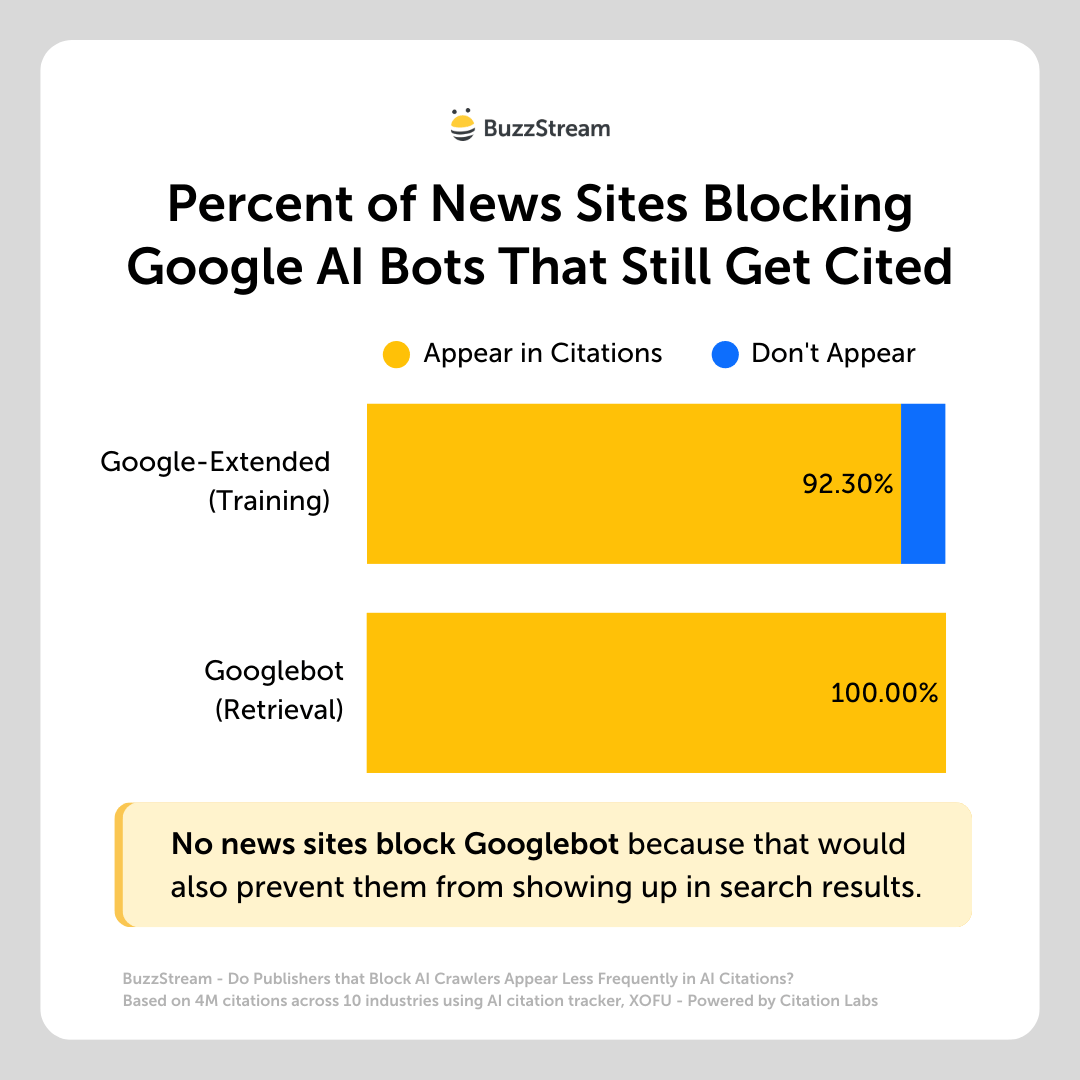
For example, yahoo.com blocks Google-Extended but appears in almost 30,000 citations.
None of the sites blocks Googlebot, which is involved in live search, because that would also prevent them from appearing in Google search results.
Overall Breakdown
So, if you wanted to look at this from an overall comparison, here’s how it would shake out:
| System | Bot | Purpose | % of cited domains blocking |
|---|---|---|---|
| OpenAI | ChatGPT-User | Live retrieval | 70.6% |
| OpenAI | OAI-SearchBot | Indexing | 82.4% |
| Google-Extended | Training | 88.2% | |
| Googlebot | Retrieval | 0% (must be indexable) |
When we look at this from the overall share of citations, it’s even more eye-opening.
Share of Citations
Roughly 70% of the citations in our dataset from ChatGPT were from sites that block ChatGPT’s retrieval bots; 95% were from sites blocked by bots used for training.
| Bot | Purpose | Citations from sites that block | Share of citations |
|---|---|---|---|
| GPTBot | OpenAI training | 5,362 | 95.4% |
| OAI-SearchBot | OpenAI indexing/search | 3,932 | 69.9% |
| ChatGPT-User | OpenAI live retrieval | 3,913 | 69.7% |
| Google-Extended | Google training | 5,362 | 95.4% |
We saw similar percentages with the Google training bots.
What’s Happening Here?
We can only take some educated guesses here, but a few thoughts are:
AI Crawlers Indexed the Page Before it Was Blocked
Publishers are getting smarter about navigating the world of AI. Some are forming partnerships with AI companies and licensing their data, while others are suing AI companies for using their data without paying.
In this case, some publishers may have learned about robots.txt later than others, meaning their data was already all over the internet beforehand.
This is perhaps the most obvious reason, but it doesn’t seem to be the case.
Most studies, like this one from Ahrefs, have shown that AI prefers “fresher content”.
Ours is no different.
I tested this on our entire dataset, and just 15% of the cited publications in our study existed before ChatGPT, and about 30% existed before AI Overviews launched .
So, Google and OpenAI are still accessing recent posts. But how?
Potentially through CCBot?
Data From These Sites Has Already Been Crawled by CCBot
If you aren’t aware, non-profit Common Crawl has been crawling and archiving the web for years. And early documentation from AI tools like ChatGPT and Gemini has already said they used CCBot.
We invited Metahan Yesilyurt to our podcast to discuss the impact of Common Crawl on AI citations.

In it, he discussed how the sites that appear in many citation studies like ours have very high occurrence rates in Common Crawl’s WebGraph, which collects data on all the crawling and indexing they do.
(You can actually check the crawl metrics of sites in Common Crawl’s dataset using Metahan’s tool.)
But then again, our study showed that about 70% of the sites blocked CCBot via robots.txt, a bot from Common Crawl.
Which brings us to another likely reason we don’t see any correlation between sites that block AI and those that show up: robots.txt doesn’t work.
AI Bots Are Circumventing Robots.txt
In our previous study, SEO with The Telegraph, Harry Clarkson-Bennett told us, “So the robots.txt file is a directive. It’s like a sign that says, ‘please keep out, but doesn’t stop a disobedient or maliciously wired robot.
Lots of them flagrantly ignore these directives.”

A Reuters report found substantial evidence of AI companies circumventing robots.txt directives, and we are confirming it with our study.
How do sites get around it?
Harry told us, “this has led to publishers being forced to use things like bot managers to block them at a CDN level.”
But, lastly, my colleague Stephen Panico brought up the inherent difference in how AI extraction works.
Robots.txt Doesn’t Block SERP Extraction
Similar to the above, but there’s a good chance robots.txt isn’t blocking the main way that these AI models get their citations.
Some AI retrieval comes from SERP-level data alone, like titles, URLs, and snippets, without ever fetching the underlying page or hitting the origin server. You can even see this in some of Google’s documentation on Vertex AI, although they don’t expressly state that they do it, of course.
This is the kind of thing that makes you click a cited source, and the exact working isn’t there, or it’s incorrect; it’s all based on previously generated snippet representations.
Realistically, it comes down to the idea that we don’t know much about how this stuff works yet. What we can do is look at the data and try to make some educated guesses.
How Should This Impact Your Digital PR Strategies?
Whether or not a news site is blocking AI crawlers shouldn’t impact your strategies one way or another.
It’s a limiting view that gets you focusing on the wrong things.
Instead of chasing links and coverage, focus on the story. Great stories can transcend singular news sites and reach other news sites, newsletters, social media, and other places where your real customers are most likely spending their time.
Vince Nero
Vince is the Director of Content Marketing at Buzzstream. He thinks content marketers should solve for users, not just Google. He also loves finding creative content online.
His previous work includes content marketing agency Siege Media for six years, Homebuyer.com, and The Grit Group. Outside of work, you can catch Vince running, playing with his 2 kids, enjoying some video games, or watching Phillies baseball.
